
In the final year of my MSc at RUG, I worked with TNO under their Greenify My Code initiative, at the intersection of software engineering, artificial intelligence, and sustainability. My goal was to answer a single question:
Can language models help us rewrite code to reduce its energy consumption?
During my early reading, I noticed that software energy consumption is usually studied from the hardware side. A great deal of work has gone into making processors, memory, and other components more efficient. I wanted to look instead at the efficiency of the code itself.
I ran experiments by executing code samples multiple times on a single bare-metal server (AMD EPYC 7543, Ubuntu 24.04.3 LTS), measuring energy through RAPL counters while a synthetic load was running to smooth out measurement spikes.
The Greenify Pipeline
The entire experiment was built as a pipeline in Python that processed 1,763 Python functions from the Mercury, HumanEval, and MBPP datasets.
The input code samples were first profiled using pyRAPL, which reads the processor’s Running Average Power Limit (RAPL) energy counters. This gave us a baseline measurement by running the test suites repeatedly for one second per code sample.
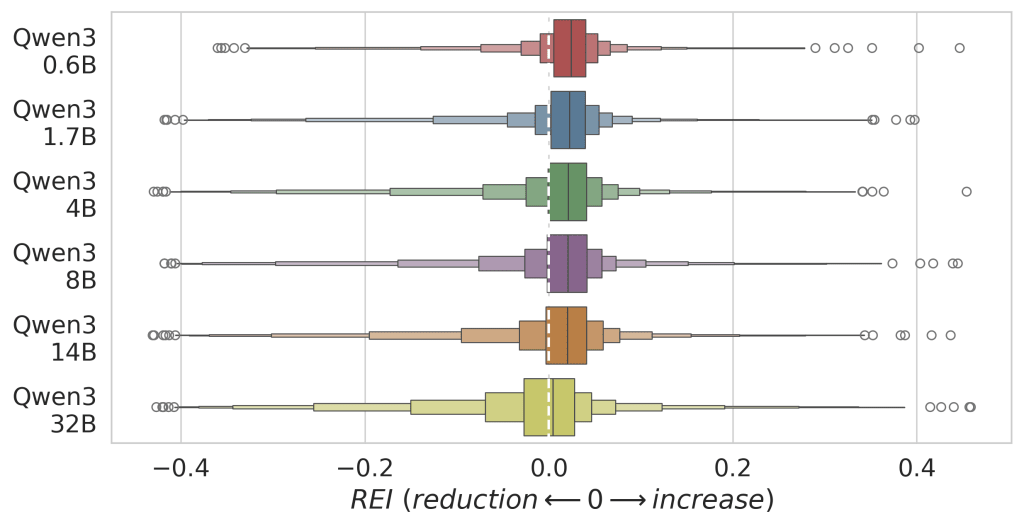
From there, the samples were sent to the Qwen3 model family, six dense models from 0.6B to 32B parameters, Q8-quantized in the GGUF format, to rewrite the code specifically for energy efficiency. I profiled these greenified samples in the same way and used tests to verify that the rewritten code remained functionally identical.
In total, more than 14,000 model-generated variants were produced and profiled to answer the question statistically.
Larger Models Tend to Perform Better
The most intuitive finding was that larger models generally performed better than smaller ones, but the relationship was logarithmic. In other words, each increase in model size brought less additional benefit than the one before it.
That effect was stronger for functional correctness than for energy-efficiency gains.
As the plot below shows, only the Qwen3 32B model clearly shifted the relative energy-impact distribution toward lower energy consumption.
The metric in the graph is Relative Energy Impact (), defined as . Negative values indicate a reduction, so means a decrease, while positive values indicate an increase in energy consumption. Zero means there was no change between the baseline and greenified code samples.
I also compared four inference strategies, varying along two axes:
input type (just-code versus code-with-suggestions from Eco Code Analyzer)
and interaction style (single-phase versus plan-then-implement), all under a chain-of-thought prompt structure.
What stood out was that the inference strategy only meaningfully shifted when paired with a specific model size. There was no single prompting style that worked best across the board; the effect depended on the model used.
Garbage In, Average Out
However, the most important finding may have been that the input code itself is the strongest predictor of potential energy savings.
If the baseline code is already efficient enough, the language model cannot improve it much further. The models are much better at exploiting obvious inefficiencies than at finding genuinely novel optimizations.
You may reasonably ask what “efficient enough” means.
From the model’s point of view, it seems to mean anything it has already learned to recognize as more efficient during training. In other words, if code starts below average efficiency, models can often improve it up to that average plateau, but not much beyond it.
That is encouraging if the goal is to automate the greenifying of code. At the same time, it shifts the harder problem from finding better models to detecting inefficient code more effectively, which led to my next question.
Predicting Energy Change
How easy is it to predict whether our greenifying process will actually reduce the energy consumption of code?
To make the process sustainable, we need to know before greenifying whether a piece of code is inefficient enough to justify the effort. That is the question I wanted to approach with machine learning.
I trained Scikit-learn models on static code-analysis metrics such as Cyclomatic Complexity and Halstead Effort to predict two outcomes:
Will the code’s functionality break? Here, the models performed well, reaching an score of . In this case, the score reflects how well the model identifies both samples whose tests will pass after greenifying and samples whose tests will fail.
For the second question, “Will the generated code reduce energy consumption?”, the models only reached an score of , which is only slightly better than random guessing at .
After further analysis, my conclusion was that the static code-analysis metrics we used do not capture the information needed to distinguish efficient code from inefficient code.
The Returns on the Energy Invested
Finally, there is an obvious trade-off to address.
While larger models produced better code, that improvement came with a real energy cost. Rewriting code with a 32B parameter model consumed significantly more power than using a smaller 7B model. Because of this, I modeled the balance between the energy cost of code generation and the energy savings from running the greenified code, considering only the variants in which greenifying actually reduced energy consumption.
The results showed that while the largest model produced the highest overall energy savings in greenified code, its break-even point, the number of times the code must run to pay back the generation cost, was worse than for all the other models.
That means model choice still matters even if we could somehow guarantee an improvement in the energy efficiency of the input code sample.
In practice, this means model selection also has to be part of the greenifying process, creating a challenging balancing act across the whole pipeline, even before accounting for model-training costs:
- Greenified code is more likely to be functionally correct if we use a larger model, so we are pushed toward the largest models possible
- Larger models generally use more energy, so we are pushed toward the smallest models possible
- Larger models tend to create larger energy savings than smaller models, but we also have to choose the model based on how often the code will run,
- because a large improvement means little if the code is rarely executed
Summary
Overall, this work points to a useful path forward for Green AI: progress does not necessarily depend on larger models.
The results suggest that, to make greenifying viable, we need to get better at identifying inefficient code before trying to optimize it. That is how we can make sure the energy spent generating code with language models is eventually paid back by the energy saved when the code runs.
This project also produced a validated dataset of energy measurements that is now available to the research community.
The dataset is published on Zenodo and HuggingFace, containing paired measurements taken before and after greenifying. I hope it supports future research, and the paper itself can be downloaded from the RUG repository.
I defended the thesis at the University of Groningen, supervised by Dr. Daniel Feitosa and Prof. Vasilios Andrikopoulos from the SEARCH software engineering group at RUG Computing Science, and Ir. Jesse van Oort from TNO Data Science.